Demystifying Columnstore Indexes
This post assumes a working knowledge of SQL Server and a basic understanding of database indexes. If you’re new to these topics, you may want to brush up on them before continuing.
I discovered Columnstore indexes while researching ways to optimize queries for my Data Warehousing team. In this article, I’ll share what I’ve learned to help others understand this powerful solution without having to sift through Microsoft documentation.
Introduction
Database indexes can be both a blessing and a curse for those seeking to optimize query performance. Optimizing indexes on SQL Server, in particular, can be a tricky task due to its ability to handle a wide range of workloads. These workloads can typically be divided into two broad categories:
- OLTP Transactions - These are real-time transaction processing scenarios that frequently update, insert, and delete individual records. Examples of such scenarios include bank transactions or flight bookings.
- OLAP Transactions - These are primarily used for analysis over transactions. In these scenarios, thousands or millions of records are scanned and aggregated together. Examples of such scenarios include data warehouses.
Standard indexes created in SQL Server are generally intended for OLTP transactions. With SQL Server 2012, a new type of indexes were introduced that were meant especially for OLAP transactions. These are columnstore indexes!
We’ll be using an employment trail table tracking millions of employees to follow throughout this post,
1
2
3
4
5
6
7
8
create table dbo.fact_employment_trail
(
id INT IDENTITY (1,1) PRIMARY KEY, -- Default clustered index column
employee_id INT NOT NULL,
employee_status NVARCHAR(30) NOT NULL, -- Contains "Active" or "Terminated"
employment_start_date DATE NOT NULL,
employment_end_date DATE NOT NULL
)
Some sample employment trails look like this, 
Note: We’re using “2100-01-01” as the end date for an open ended record.
Before we dive into the specifics of columnstore indexes, let’s take a moment to review how tables and rows are typically stored on disk. In traditional rowstore storage, data is organized row by row, with all data belonging to a single row stored together. This storage format is used by heaps and B-tree based indexes. It’s well-suited for OLTP transactions, which typically seek a particular key and retrieve the entire row. However, it may not be the most efficient storage method for OLAP transactions.
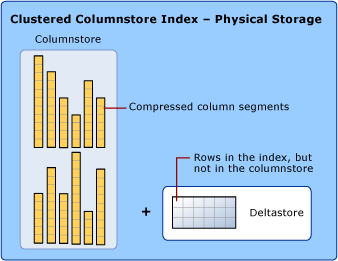
Columnstore storage is a storage format that differs from rowstore by emphasizing columns over rows. In this format, tables are logically organized as a table with rows and columns, but physically stored in a column-wise data format. This unique storage format creates opportunities for a whole new set of optimizations, making columnstore indexes a powerful tool for improving query performance. When a table has a clustered columnstore index, columnstore storage is the data format in which the table is physically stored.
1
CREATE CLUSTERED COLUMNSTORE INDEX cci ON dbo.fact_employment_trail;
Architecture
To truly understand how Columnstore Indexes benefit OLAP queries, it’s important to understand how it’s implemented in SQL Server.
Rowgroups
Every table is split into groups of approximately a million rows before being stored on disk. These groups are called rowgroups. Rowgroups are a key feature of columnstore indexes because they allow for efficient compression and processing of data. Each rowgroup is compressed independently, which allows for better compression ratios and faster query performance. Additionally, rowgroups can be processed in parallel, which can further improve query performance on large datasets.
In our example, the table fact_employment_trail consists of ~ 4 million rows, which get split into 4 separate row groups. 
1
2
3
4
5
6
7
8
9
SELECT OBJECT_NAME(object_id) as object_name,
row_group_id,
state_desc,
total_rows,
size_in_bytes,
trim_reason_desc
FROM sys.dm_db_column_store_row_group_physical_stats
WHERE object_id = OBJECT_ID('fact_employment_trail')
order by row_group_id
Column Segments
In columnstore storage, each column in a table is compressed and stored together as a column segment. The index also stores metadata per column segment for efficient filtering and querying, sometimes without decompressing the data. This compression allows the query engine to reduce memory footprint and to operate on multiple rows together, making it particularly helpful. There is one column segment for every column in the table.
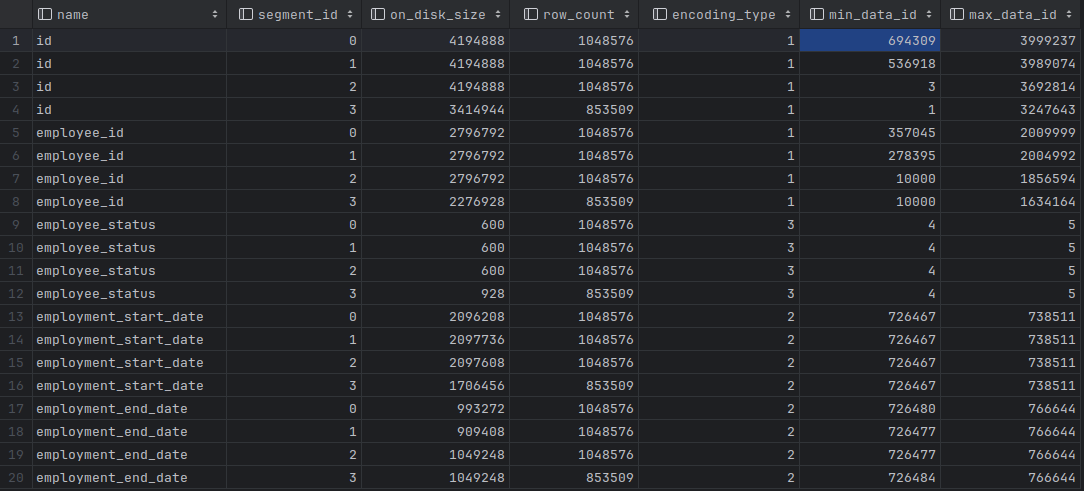
fact_employment_trail has 20 column segments since it has 4 row groups and 5 columns in the table. The below image shows that employee_status and the date columns are compressed more efficiently than id and employee_id due to the nature of data.
1
2
3
4
5
6
7
8
9
10
SELECT c.name, s.segment_id,
s.on_disk_size, s.row_count, s.encoding_type, s.min_data_id, s.max_data_id
FROM sys.column_store_segments AS s
INNER JOIN sys.partitions AS p
ON s.hobt_id = p.hobt_id
INNER JOIN sys.indexes AS i
ON p.object_id = i.object_id
INNER JOIN sys.columns AS c
ON c.column_id = s.column_id AND c.object_id = p.object_id
WHERE i.type in (5, 6) and i.name = 'cci'
Deltastore
Columnstore indexes optimize updates and deletes by using temporary clustered B-Tree indexes called delta rowgroups, collectively known as the Deltastore. These intermediate rowstore rowgroups speed up inserts and deletes by avoiding de-compressing the column segments. SQL Server merges results from both the compressed column segments and the deltastore to handle queries.
A background process takes care of merging rows from the deltastore into the columnstore index when the number of rows reaches a threshold.
Behavior
As mentioned at the outset, SQL Server promotes columnstore indexes explicitly for Data Warehouse fact tables that store millions of rows. According to the official documentation, “achieve gains up to 10 times the query performance in your data warehouse over traditional row-oriented storage”. The major workload of DWH tables are OLAP queries that scan millions of rows and apply aggregates on top of it.
What makes traditional rowstore indexes bad for analytics workloads?
- Since most OLAP queries only require a few columns, traditional indexes can be inefficient as they retrieve entire rows from disk or memory before processing the result. This can result in wasteful I/O, including the retrieval of expensive
nvarchar(max)orvarbinary(max)columns. - DWH data is typically read-only and is stored in large tables with many columns. Rowstore indexes store data in a row-wise format, which means that each row is stored together on disk. This makes it difficult to compress the data efficiently, which can lead to slower query performance and higher storage costs.
What makes columnstore indexes good for analytics workloads?
- Columnstore indexes are ideal for large fact tables commonly used in Data Warehouses, which can have millions of rows and hundreds of columns. By allowing queries to ignore unnecessary column segments, columnstore indexes significantly reduce I/O overhead for analytics queries that typically use only a few columns
- Columnstore indexes are particularly efficient at compressing data when columns store values of the same type and domain, especially when the column takes only a finite number of values. This results in significant storage cost reductions and faster query processing due to the reduced amount of data being worked with.
- SQL Server’s Batch Mode Execution feature processes batches of rows together in a columnstore index, resulting in up to 2 times faster query performance.
What makes columnstore indexes bad for transactional workloads?
- Microsoft recommends against using columnstore as the primary data storage format for tables with high numbers of inserts, updates, and deletes (typical of OLTP workloads), as the overhead of updating the index can be significant. While SQL Server does maintain a separate deltastore index for faster updates, this can add overhead when querying.
- Columnstore indexes may not be the best choice when retrieving details from only a few rows, such as all employment stints of an employee, due to the overhead of decompressing individual column segments to obtain the required values.
- Columnstore indexes may not perform well when the number of rows is less than a million, as compression efficiency increases with larger row counts. Additionally, SQL Server cannot parallelize query operations if there is only one row group.
Choosing the right design
SQL Server introduced nonclustered columnstore indexes which open up the opportunity for mixed workloads without having to use just one data storage format or the other.
Case #1: Mostly Analytics Queries, Sometimes OLTP Queries
In this scenario, you can use,
- Clustered Columnstore Index - Table is stored physically in columnstore format. This speeds up most analytics queries. Inserts, Updates, and Deletes will still be slow.
- Non-Clustered Rowstore Indexes - If the kind of transactional SELECT queries are known beforehand, they can be optimized using non-clustered rowstore indexes.
This is a good combination for Data Warehouses where we also need to speed up queries that search for specific values.
Case #2: Mostly OLTP Queries, Sometimes Analytics Queries
If the goal is to primarily have an OLTP Database that also supports analytics queries, use this design.
- Clustered Rowstore Index - Standard queries that seek (rather than scan) data are efficient. Inserts, Updates, and Deletes are quick.
- Non-Clustered Columnstore Indexes - Create these indexes to optimize analytics queries as well.
This is only a very rough approximation. Refer the Design Guidance by Microsoft for further details.
Results
1
2
3
4
5
6
7
8
select * -- OLTP Query. Employment details of a single employee.
from dbo.fact_employment_trail
where employee_id = '10035'
select count(*) -- OLAP Query. Number of Active employees today.
from dbo.fact_employment_trail
where employee_status = 'Active'
and CURRENT_TIMESTAMP between employment_start_date and employment_end_date
Following are the CPU Times taken for each of the above queries using a columnstore index and a rowstore index.
| OLAP Query | OLTP Query | |
|---|---|---|
| Columnstore | 250 ms | 16 ms |
| Rowstore | 640 ms | 1 ms |
Note: The rowstore clustered index is created on employee_id.
Conclusion
The following popular quote bears repeating,
The first rule of optimization is: Don’t do it. The second rule of optimization (for experts only) is: Don’t do it yet. Measure twice, optimize once.
Columnstore indexes are a powerful tool for improving query performance in SQL Server, particularly for analytics workloads. However, it’s important to choose the right index type for your workload, as rowstore indexes may be more appropriate for OLTP queries that require fast access to individual rows. Overall, columnstore indexes are a valuable addition to the SQL Server indexing toolkit, and can help improve the performance of your application.
✨ Follow me on Twitter to read more like this :)